经典开源NLP工具包,提供全面的自然语言处理算法和丰富的语料库资源,是学术研究和教学的首选平台
一、工具概览
基本信息:
- 名称:NLTK (Natural Language Toolkit)
- 开发方:宾夕法尼亚大学Steven Bird和Edward Loper教授主导开发
- 定位:Python自然语言处理综合工具包
- 许可证:Apache 2.0开源许可证
- 支持平台:Windows、macOS、Linux
- Python版本要求:3.8-3.12
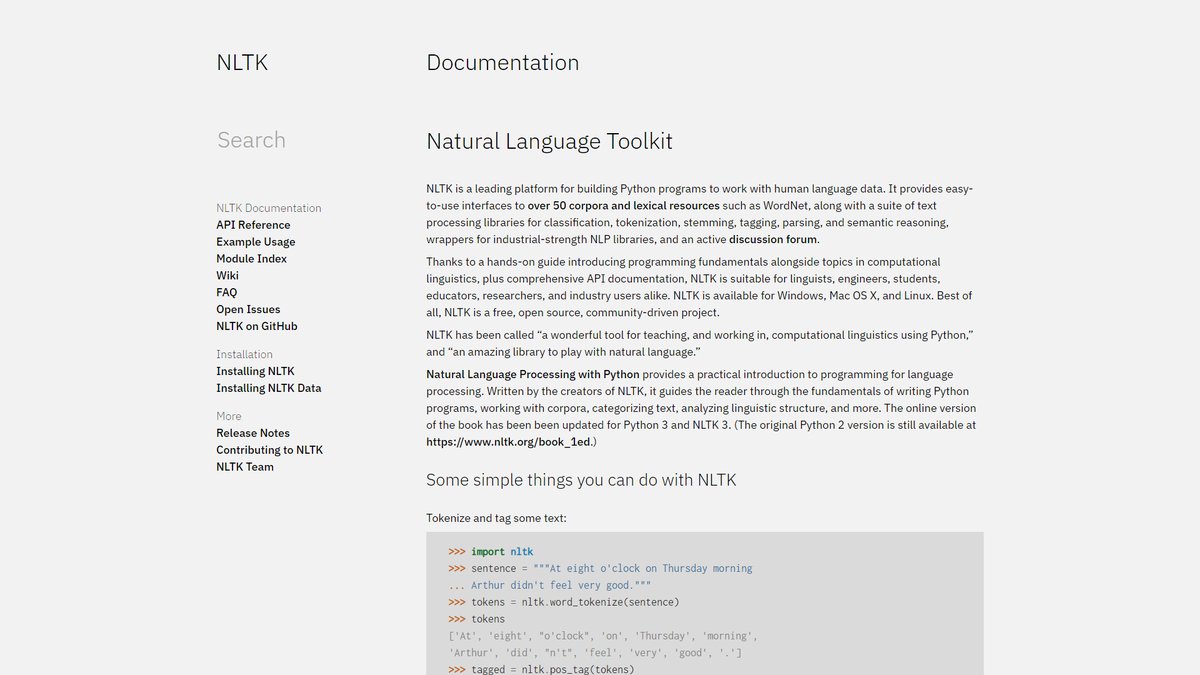
NLTK是一个领先的平台,用于构建处理人类语言数据的Python程序,提供了超过50个语料库和词汇资源(如WordNet)的易用接口,以及一套用于分类、分词、词干提取、标记、解析等文本处理库。作为自然语言处理领域的经典工具包,NLTK自2001年诞生以来,已成为计算语言学教学和研究的重要基础设施。
NLTK已成功用作教学工具、个人学习工具以及原型开发和构建研究系统的平台,目前在美国有32所大学和25个国家的教育机构在其课程中使用NLTK。该工具包不仅是研究人员的得力助手,也是初学者进入NLP领域的理想起点,其丰富的文档资源和教学材料为用户提供了完整的学习体系。
二、核心功能解析
2.1 文本预处理能力
NLTK在文本预处理方面提供了全面的功能支持。其分词功能可以将文本分解为单词或句子,作为许多NLP任务的基础步骤。系统支持多种分词策略,包括基于空格的简单分词和更复杂的语法感知分词。
在词干提取方面,NLTK实现了多种算法,包括Porter Stemmer、Snowball Stemmer等,可以将单词简化为词根形式,虽然速度较快但准确性相对较低。相比之下,词元化功能基于WordNet的内置形态函数,能够提供更准确的词根形式识别。
2.2 语言学分析工具
NLTK的词性标注功能可以分析每个单词在句子中的语法角色,支持超过50种语言的处理。命名实体识别(NER)功能能够识别文本中的人名、地名、组织名等实体信息,为信息抽取提供基础。
句法分析是NLTK的另一个强项,提供了多种解析器来分析句子的语法结构并生成句法树。这些工具对于深入理解文本的语言学特征具有重要价值。
2.3 机器学习集成
NLTK与scikit-learn等机器学习库的集成使其能够将机器学习算法应用于文本数据,用于文本分类和情感分析等任务。工具包内置了多种分类算法,包括朴素贝叶斯、决策树等,为用户提供了开箱即用的文本分类解决方案。
2.4 语料库和语言资源
NLTK最大的优势之一是其丰富的语料库资源。工具包提供了超过50个语料库和词汇资源,包括WordNet等重要的语言学数据库,为研究和开发提供了宝贵的训练数据。
三、商业模式与定价
3.1 开源免费模式
NLTK源代码在Apache 2.0许可证下分发,这是一个免费、开源、社区驱动的项目。Apache 2.0许可证是一个宽松的开源许可证,允许商业使用、修改和分发,为企业和个人用户提供了极大的使用自由度。
3.2 可持续发展机制
作为学术主导的开源项目,NLTK主要依靠以下方式维持发展:
- 学术机构的资助支持
- 社区贡献和志愿开发
- 相关培训和咨询服务的间接收益
- 企业捐赠和赞助
这种模式确保了工具的持续更新和维护,同时保持了其非营利性质和教育导向。
3.3 成本效益分析
对于用户而言,NLTK提供了极高的性价比:
- 零许可费用:完全免费使用,无需支付任何授权费
- 丰富资源:内置大量语料库和预训练模型
- 学习成本:虽然学习曲线较陡峭,但拥有完善的文档和教程
- 维护成本:开源性质意味着用户可以自主定制和维护
四、适用场景与目标用户
4.1 学术研究和教学
NLTK特别适合语言学家、工程师、学生、教育工作者、研究人员和行业用户,其全面的API文档和计算语言学入门指南使其成为理想的教学工具。在学术环境中,NLTK被广泛用于:
- 计算语言学课程教学
- NLP研究项目开发
- 语言学理论验证
- 学术论文实验设计
4.2 原型开发和概念验证
NLTK作为一个完整的自然语言处理算法工具箱,特别适合研究人员从零开始构建复杂的NLP功能。对于需要快速验证NLP概念的项目,NLTK提供了理想的实验环境。
4.3 小到中规模文本分析
NLTK适合处理以下类型的文本分析任务:
- 学术文献分析
- 社交媒体数据挖掘
- 客户反馈情感分析
- 文档分类和信息抽取
- 语言学习工具开发
4.4 不适用场景
需要注意的是,NLTK在以下场景中可能不是最佳选择:
- 大规模生产环境:性能相对较慢,不适合高并发应用
- 实时处理需求:响应速度不如spaCy等工具
- 深度学习项目:对现代神经网络模型支持有限
五、市场地位与竞品对比
5.1 与spaCy的对比
与NLTK相比,spaCy在开发和生产环境中更有用,因为它提供了比NLTK更快速和准确的语义分析。研究人员通常更偏爱NLTK,因为它有各种算法。
主要差异:
- 设计理念:NLTK注重算法多样性和教学价值,spaCy专注于生产效率
- 性能表现:spaCy在速度上远超NLTK(spaCy用Cython编写),但NLTK内存占用更小
- 使用复杂度:NLTK需要更多代码实现功能,spaCy接口更简洁
- 语言支持:两者都支持多种语言,但spaCy的预训练模型更丰富
5.2 与TextBlob的对比
TextBlob基于NLTK和Pattern构建,为常见NLP操作提供了优秀的API,更专注于日常使用,但继承了NLTK的低性能问题。TextBlob可以看作是NLTK的简化版本,适合初学者快速上手。
5.3 市场定位分析
在F1评分对比中,NLTK和spaCy在文本分类任务中表现最佳,这表明NLTK在算法准确性方面依然具有竞争力。NLTK在以下方面保持优势:
- 教育市场:无可替代的教学地位
- 研究领域:丰富的算法实现和实验工具
- 定制化需求:高度可配置的模块化设计
- 语料库资源:最丰富的内置语言资源
六、用户体验评价
6.1 学习曲线和易用性
NLTK比spaCy更全面,但大量可用功能可能会让初学者感到困惑,而且该库通常需要更多代码来完成某些NLP任务。尽管存在学习门槛,但NLTK提供了:
- 详细的在线文档和教程
- 经典教材《Natural Language Processing with Python》
- 丰富的示例代码和案例研究
- 活跃的社区支持
6.2 社区生态系统
NLTK拥有庞大而多样化的社区,长期以来一直是自然语言处理教学的标准工具。社区特点包括:
- 学术导向:大量研究人员和教育工作者参与
- 资源丰富:教程、书籍和在线讨论论坛众多
- 国际化:在全球范围内被广泛使用和教授
- 稳定性:项目历史悠久,代码成熟稳定
6.3 技术支持质量
作为学术项目,NLTK的技术支持主要通过以下渠道:
- 官方文档和API参考
- GitHub问题追踪系统
- 邮件列表和在线论坛
- 学术会议和研讨会
虽然没有商业级的专业支持,但社区响应通常比较及时,特别是对于教学和研究相关的问题。
6.4 安全性和隐私
NLTK语料库在每个语料库的README文件中给出的条款下提供,所有语料库都可重新分发并可用于非商业用途。作为开源项目,NLTK的安全性具有以下特点:
- 代码完全开放,安全问题可被及时发现
- 学术背景确保了项目的非营利性质
- 数据处理本地化,无隐私泄露风险
- 符合GDPR等数据保护法规要求
总结评价
推荐指数:★★★★☆
NLTK作为自然语言处理领域的经典工具包,在教育、研究和原型开发方面具有不可替代的价值。其丰富的算法实现、完善的文档资源和强大的社区支持,使其成为NLP学习和研究的首选平台。
主要优势:
- 完全免费开源,使用门槛极低
- 功能全面,覆盖NLP各个方面
- 教学资源丰富,学习体系完整
- 社区活跃,生态系统成熟
- 高度可定制,适合研究需求
主要局限:
- 性能相对较慢,不适合大规模生产
- 学习曲线陡峭,需要一定编程基础
- 现代深度学习支持有限
- 部分功能实现较为复杂
适用建议:
- 强烈推荐:NLP初学者、研究人员、教育工作者
- 推荐:原型开发、学术项目、小规模文本分析
- 需谨慎考虑:大规模生产环境、实时处理需求、深度学习项目
NLTK的价值不仅在于其技术实现,更在于其在NLP教育普及和学术研究中发挥的重要作用。对于希望深入理解自然语言处理原理和技术的用户,NLTK仍然是最佳的选择之一。
